Route 53で実現するグローバル・ロードバランシング(DNSフェイルオーバー)

この記事の目次
はじめに
本記事では、AWSのDNSサービス「Route 53」を使って、地理的に分散したシステム環境で高可用性を実現する「グローバル・ロードバランシング(GSLB)」の構成方法を解説します。特に、障害発生時に自動で正常系へ切り替える「DNSフェイルオーバー」設定に焦点を当て、設定手順や注意点を実践的に紹介します。
この記事を読むことで以下がわかります。
- GSLB構成の概要と特徴
- Route 53を用いたフェイルオーバー設定の具体的手順
- 安定運用のための設計上の注意点
グローバル・ロードバランシング(GSLB)とは
GSLB(Global Server Load Balancing)とは、地理的に離れた複数のサーバーやデータセンター間で、ユーザーのアクセスを最適な拠点に振り分ける仕組みです。クライアントに最も近い、あるいは最も応答の速いサーバーへ接続させることで、Webサイトやアプリケーションの表示速度を向上させることができます。また、特定のサーバーや拠点で障害が発生した場合でも、正常な別の拠点へ自動的に切り替えることで、システムの停止を防ぐことが可能です。
このようにGSLBは、パフォーマンスの最適化と障害時の可用性確保を両立できる手法として、多くのWebサービスや業務システムで活用されています。
Route 53でGSLBを利用するメリット
高可用性と信頼性
Route 53は、AWSサービスの中でも唯一SLA 100%が保証されているDNSサービスです。ヘルスチェック機能とフェイルオーバー構成を組み合わせることで、障害発生時でも自動的に正常な環境へ切り替えが可能となり、高い可用性と信頼性を確保できます。
多彩なルーティングポリシー
レイテンシーや地理情報に基づいたトラフィック分散が可能で、ユーザーに最適な接続先を動的に選択できます。また、重みづけによるトラフィックの割合調整や、フェイルオーバー構成と組み合わせた柔軟なルーティングも実現可能です。
管理の容易さ
AWSマネジメントコンソール上で直感的に操作できるため、DNSの専門知識がなくても導入や運用が容易です。
コスト効率
DNSクエリー数に応じた従量課金制のため、一昔前のハードウェアベースのソリューションと比べ初期費用を抑えて運用コストを低減できる可能性があります。
GSLBの利用シーン
GSLBは、システムの可用性や冗長性を高めるさまざまな場面で活用できます。代表的なユースケースは以下のとおりです。
ユースケース①:災害対策等のDR構成(Active/Standby)
- 災害などでメインサイト(Active)が利用できなくなった場合でも、別拠点にある待機系(Standby)へ自動的に切り替えることで、サービスの継続を実現できます。災害対策(DR:Disaster Recovery)として有効な構成です。
ユースケース②:マルチクラウドで負荷分散(Active/Active)
- AWSと他のクラウドサービス(例:国内クラウド)を併用し、複数の環境でシステムを同時に稼働させることで、トラフィックを分散しつつ冗長性も確保できます。障害時の影響範囲を限定し、性能面の最適化にも寄与します。
ユースケース③:障害時に備えたソーリーページの自動表示
- システム障害などによりサイトが停止した場合でも、ヘルスチェックにより自動的に「メンテナンス中です」や「障害発生中」などのソーリーページを切り替えることができます。ユーザーへの影響を最小限に抑え、信頼性の低下を防ぎます。
GSLB構成の設定手順
ここでは、AWS Route 53を用いたGSLB構成の具体的な手順を紹介します。DNSフェイルオーバーの仕組みを活用し、障害発生時に自動で待機系に切り替わる構成を想定しています。
前提条件
- ドメインはすでにRoute 53で運用中
- Active側のダウンを検知するとStandby側に切り替わる構成
- ActiveとStandbyの環境はそれぞれ別のクラウド環境
(Route 53はAWS外のホストに対してもヘルスチェックが可能です)
ヘルスチェックの作成手順
Step.1:AWSマネジメントコンソールにアクセスし、Route 53の「ヘルスチェック」セクションを開きます。
Step.2:Route 53>ヘルスチェック>「ヘルスチェックの作成」をクリックします。
Step.3:Active環境用、Standby環境用の2つのヘルスチェックを作成します。
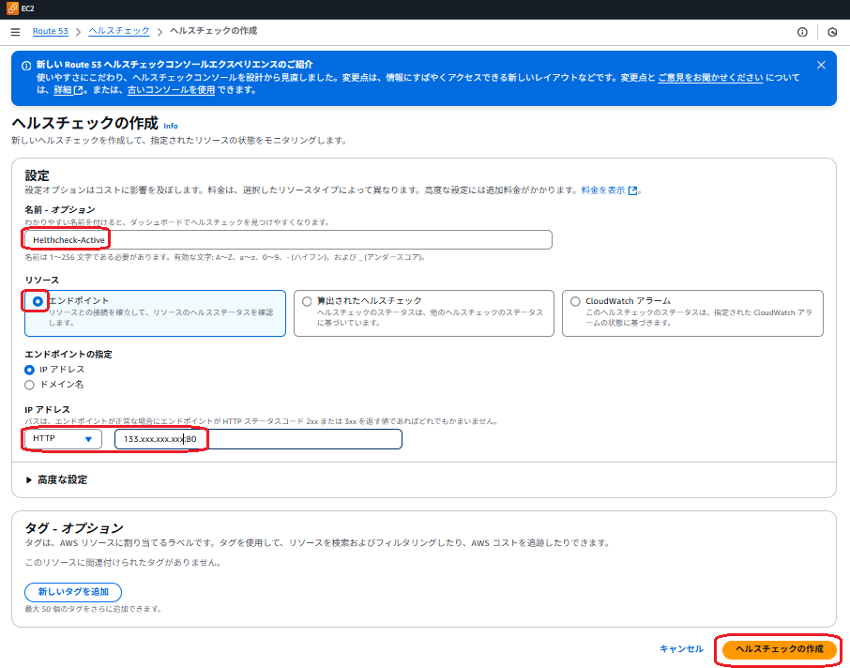
Step.4 各種設定は以下のとおりです。
- 名前・オプション:任意のわかりやすい名称を入力します。
- リソース:「エンドポイント」を選択します。
- エンドポイントの指定:「HTTP」(SSL証明書があれば「HTTPS/443」)を指定し、拠点の「グローバルIPアドレスとポート番号」を入力します。
- 「ヘルスチェックの作成」をクリックします。
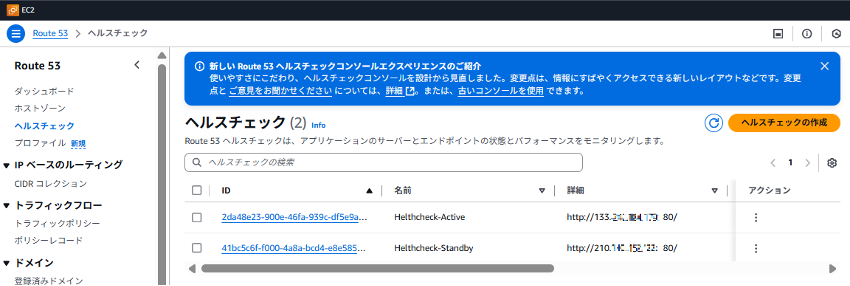
Step.5:2つのヘルスチェックが作成できました。
DNSレコードとルーティングポリシーの設定
Step.1:Route 53のダッシュボードに戻り、対象ドメインのDNS管理を開きます。
Step.2:対象のホストゾーン(ドメイン)を選択します。
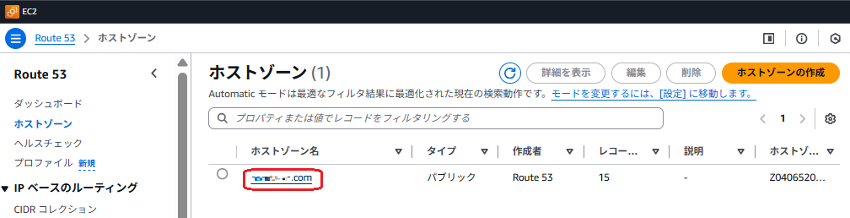
Step.3「レコードを作成」をクリックします。
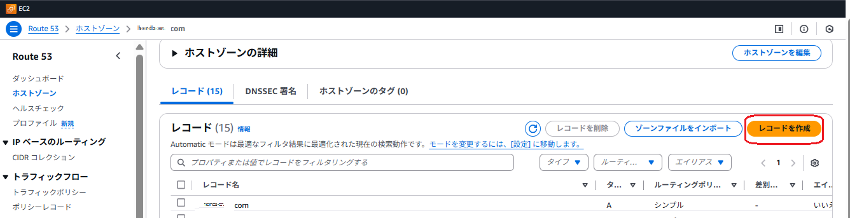
Step.4:ルーティングポリシーの選択と設定
Active環境用、Standby環境用の2つのレコードを作成します。設定項目は以下のとおりです。
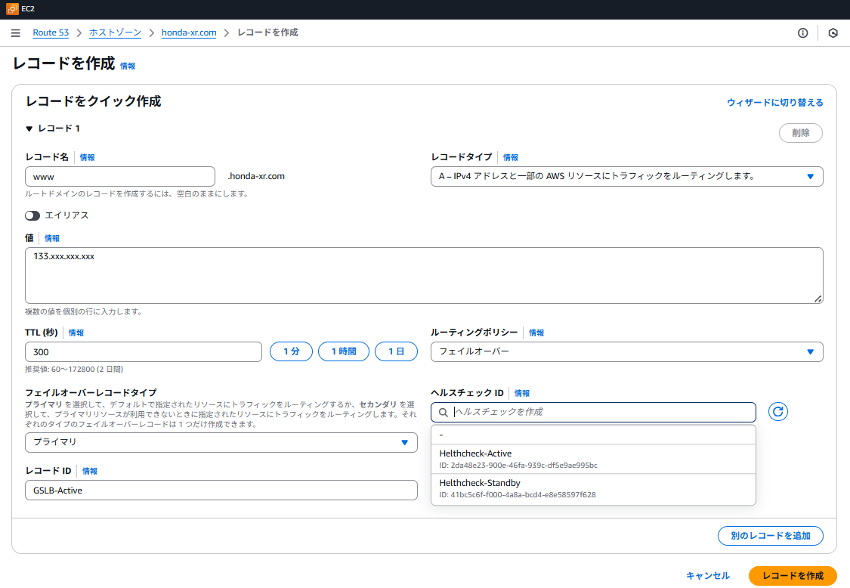
- レコード名:例)www
- タイプ:Aレコード
- 値(IPアドレス):各環境のグローバルIP
- TTL:短め(例:60秒)を推奨
- ルーティングポリシー:フェイルオーバー
- フェイルオーバーレコードタイプ:プライマリ(Active)/セカンダリ(Standby)
- ヘルスチェック:先ほど作成したIDを指定
- ヘルスチェックID:プルダウンで先ほど作成した「ヘルスチェック」のIDが表示されますので、Active用・Standby用をそれぞれ選択。
- レコードID:そのレコードを識別できるわかりやすい任意の名前をつけます。ここでは「GSLB-Active」と「GSLB-Standby」としました。
以上入力したら「レコードを作成」をクリックします。
作成されたレコードは以下のとおりです。

設定後の動作確認
Route 53によるGSLB構成が正しく動作するかを確認します。障害時の挙動とDNSレベルの切り替えが意図通りに動いているかを検証しましょう。
- FQDNにアクセスし、正常時にActive環境が表示されることを確認します。
- 次に、Active側のWebサーバーを一時的に停止し、Standby側への切り替えが行われることを確認します。
- dig コマンドなどでDNS応答が切り替わっているかをチェックすることで、フェイルオーバー動作を検証できます。
上記設定に合わせて簡単なテストページを両環境に用意しました。URLバーにIPアドレスを入力するとそれぞれページが表示されます。
障害発生時の切り替えテスト
まず、想定される障害を再現するために、Active側のWebサーバーを一時的に停止します。この状態で、Route 53のDNSフェイルオーバー機能が働き、Standby側に自動的に切り替わるかを確認します。
この検証のため、Active環境・Standby環境のそれぞれに簡易なテストページを設置しておくとわかりやすくなります。
- Active用 http://133.xxx.xxx.xxx/
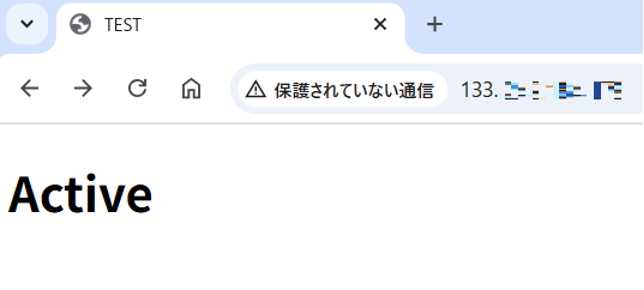
- Standby用 http://210.xxx.xxx.xxx/
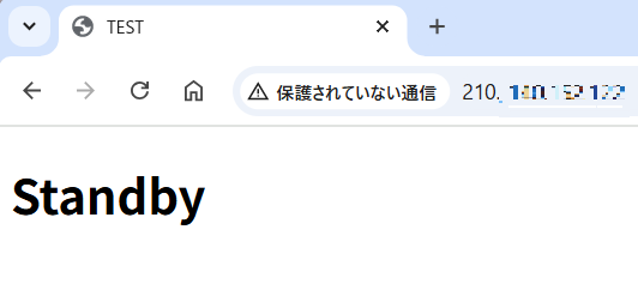
Webブラウザでの確認
障害発生前は、FQDNにアクセスするとActive側のページが表示されます。
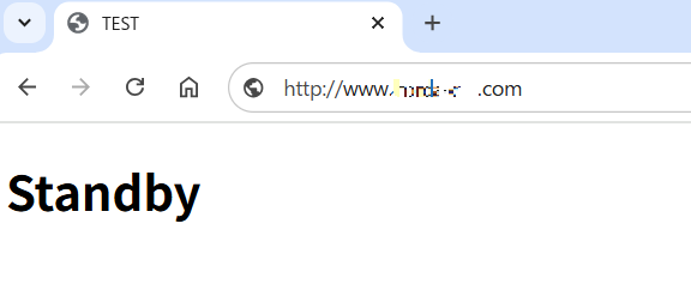
障害発生後(Active側の停止後)は、自動的にStandby側の環境が表示されるはずです。ブラウザで再度FQDNにアクセスし、切り替えが反映されているかを確認しましょう。
- 設定したFQDNを入力するとActive側が表示されます。
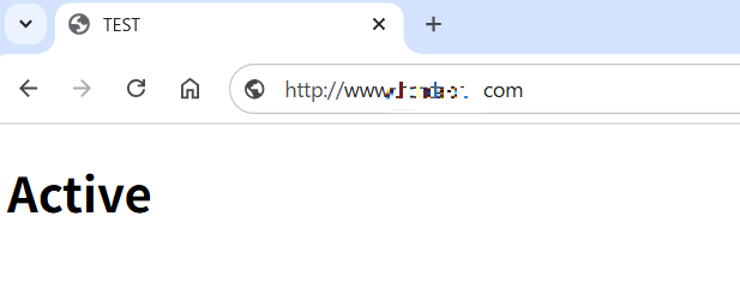
障害を想定してActive側のWebサーバーを停止すると・・・Standby側に切り替わりました。
digコマンドによるDNS応答確認
CLI(コマンドライン)から、digコマンドを使用してDNSの切り替わり状況を確認することも可能です。以下は、対象ドメインのネームサーバーを指定して、該当FQDNのIPアドレスを問い合わせる例です。
●(正常時)Active側のWebサーバーが稼働している時
$ dig www.example.com @ns-1195.awsdns-21.org +short
133.xxx.xxx.xxx ←Active側のホストのIPアドレス
●(異常時)Active側のWebサーバーが停止している時
$ dig www.example.com @ns-1195.awsdns-21.org +short
210.xxx.xxx.xxx ←Standby側のホストのIPアドレス
このように、DNSレベルで正常に切り替わっていることを確認できます。
GSLB設定時の注意点
GSLB構成を安定して運用するためには、DNSとヘルスチェックの特性を正しく理解し、以下の点に留意する必要があります。
ヘルスチェック間隔とタイムアウト設定の留意点
Route 53のヘルスチェックは、標準設定で30秒間隔、3回連続でチェックが失敗すると「異常」とみなされます。つまり、障害検知までに最大で90秒の遅延が生じる可能性があります。チェック間隔は短いほうが検知・切替わりが早く、最短で10秒にすることも可能ですが追加コストが発生します。
タイムアウト値は変更することができませんが、http/httpsの場合は以下のとおりで約6秒になります。
- TCP接続を確立:最大4秒
- レスポンスの最初のバイトを受信するまで:最大2秒
さらに、閾値(失敗回数)を必要以上に短く設定すると、ネットワークの一時的な揺らぎを障害と誤認し、フェイルオーバーが頻繁に発生する「フラッピング現象」を引き起こす可能性があります。
閾値をチューニングする際は、環境にあわせて何が最適か実環境に応じて段階的な検証を行うことを推奨します。
DNSキャッシュ(TTL)の影響
DNSのキャッシュ(TTL)が長いとヘルスチェックで異常を検知しIPアドレスが切り替わっても、DNSサーバーや端末に古い情報がキャッシュされている間は、新しいIPアドレスにアクセスされません。そのため短めに設定することが望ましい設定ではありますが、Route 53ではクエリー数に応じた従量課金制ですので利用料が増えてしまう懸念があります。サービス特性や予算に応じたTTL設計が重要です。
まとめ
AWSでシステムを構築する際に、マルチAZやクロスリージョンなど冗長構成を柔軟に組んで構築・運用することが可能です。高い可用性と耐障害性を確保することができるわけですが、システムの設計・構築や運用にはノウハウが必要になりコストも膨大になります。
冗長構成が必須要件だとしても、今回のようなGSLB構成を組むことで他の安価なクラウドサービスに切り替えてシステムを継続運用することが可能です。
ただし、GSLB構成は切り替えだけで障害対応が完結するわけではありません。切り替え後の運用対応や、原因調査・復旧作業なども含めて対応できる体制が求められます。
「ベアサポート」では、AWS環境だけでなく複数クラウド環境の設計・構築経験があり、24時間365日の監視障害対応を行うことが可能です。さまざまなインフラ運用を経験しているため、システムの安定稼働に課題がある方はぜひお問い合わせください。